1. 往返路上
从家里到伊通河绿道中间这一段,骑自行车10多分钟,坐公交车20分钟左右。在换乘自行车之前,要去小卖店买水。
今天这家店的外面刚好看到一只麻雀,嘴里叼一个很大的黄色的东西,在铁架子上跳来跳去。说黄色的乌西很大,当然是和麻雀的体型相比,大概有1/4脑袋那么大吧,看起来不像活物,但应该是食物。拍了几张照片。
进店之后,脉动没有找到我想要的青柠口味。问小伙子老板。小伙子老板说,有有有,在这儿呢,不过这些是常温的。声音有点有气无力。我跟进去,老板说在那个屋。我拐过去,感慨店真大呀。架子上有好多瓶儿,全都是猫薄荷3D口味的。3D是什么不知道,猫薄荷什么味儿我也不知道。但是薄荷我不喜欢,太像牙膏了。旁边有小号儿的脉动青柠口味,我一猜性价比就会更低,但是没办法。
往外走,刚好遇到小伙子老板的估计是他爸爸。老老板热情地说,没找到想要的?在这儿呢。就是门口那些,我说那口味我不想要,要么就是桃子,要么就是什么的。心想,反正是粉红色的,不是青柠。冰箱里还有,我说我想找常温的,就到这个吧。
在收款台站了一会儿,没人吱声儿,我问多少钱。小伙子老板说7块。通常这时候我大脑连反应都不反应,就按数字,但是7块刚好是我很熟的数字,这几天我买两瓶饮料的价钱就这些钱。我说大瓶的价格加起来是7块,小瓶的也7块吗?老老板说6块,泉阳泉两块。

回程坐公交,还是227,跟昨天一样。司机大叔还是穿坎袖儿,还是带了一个红袖标,光出溜的戴在胳膊上。让我想起以前看到的说法,非洲人民学习毛泽东思想,非常热衷,戴像章的时候,没有衣服就别在胸口的皮肤上。估计袖标是要求必须带。
拍了张照片留念,我俩都戴墨镜,像不像俩特工?

2. 大桥下的生态
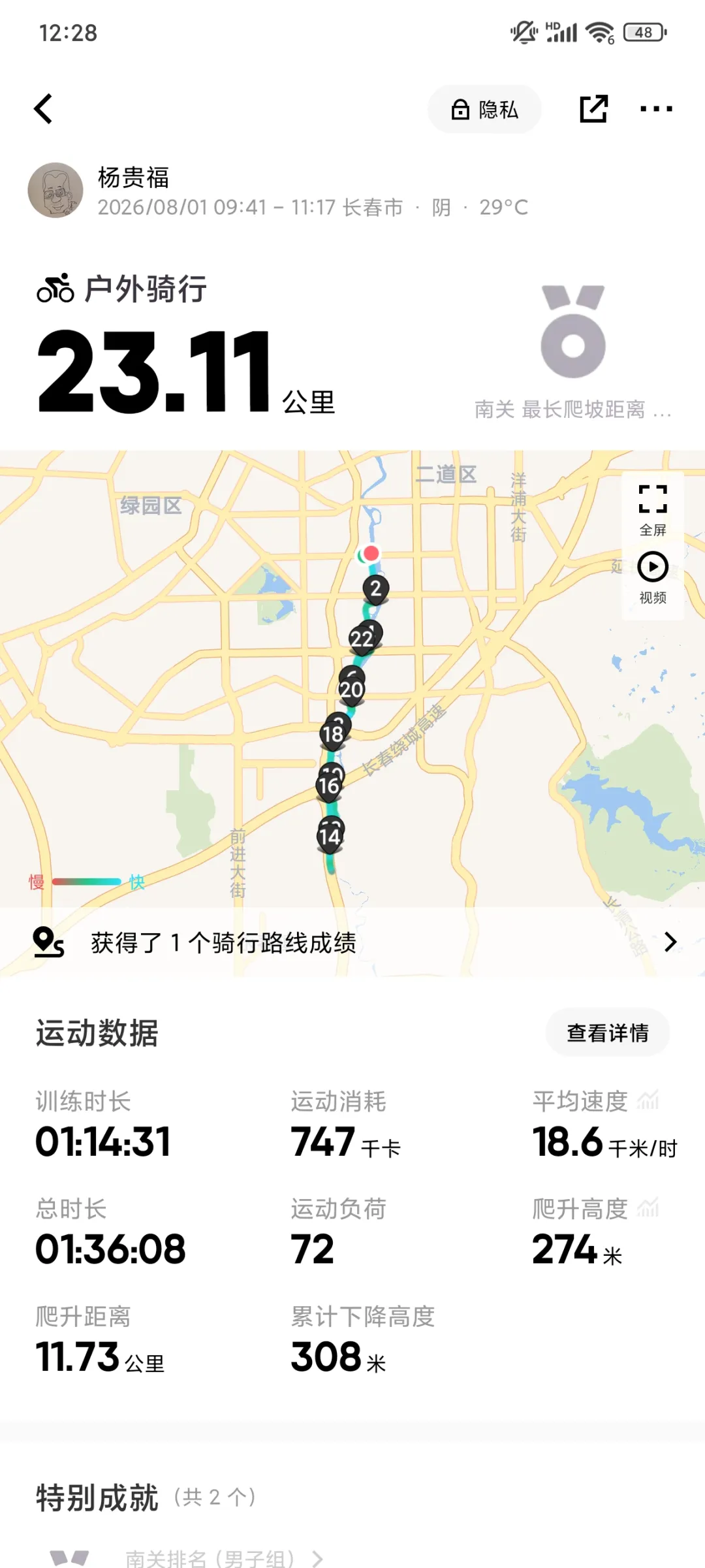
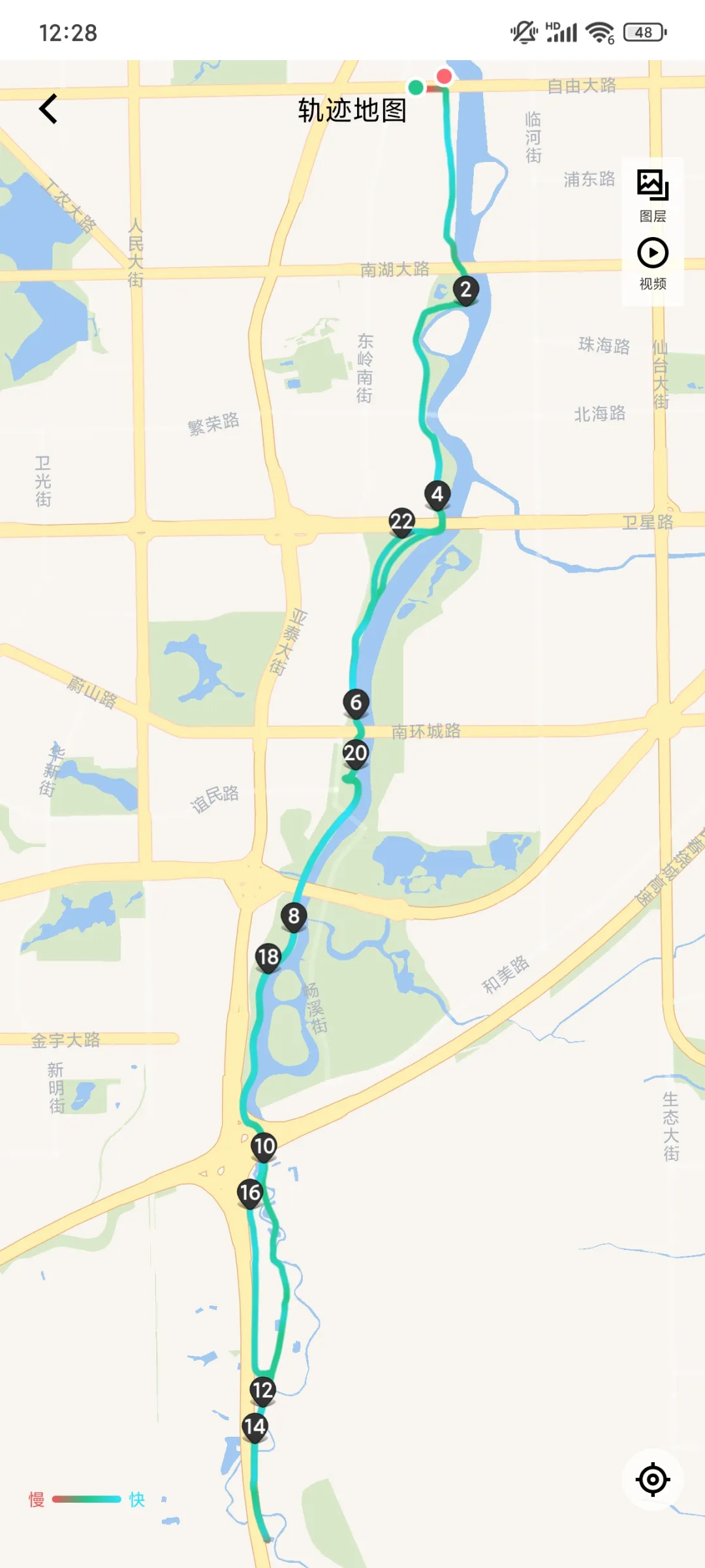
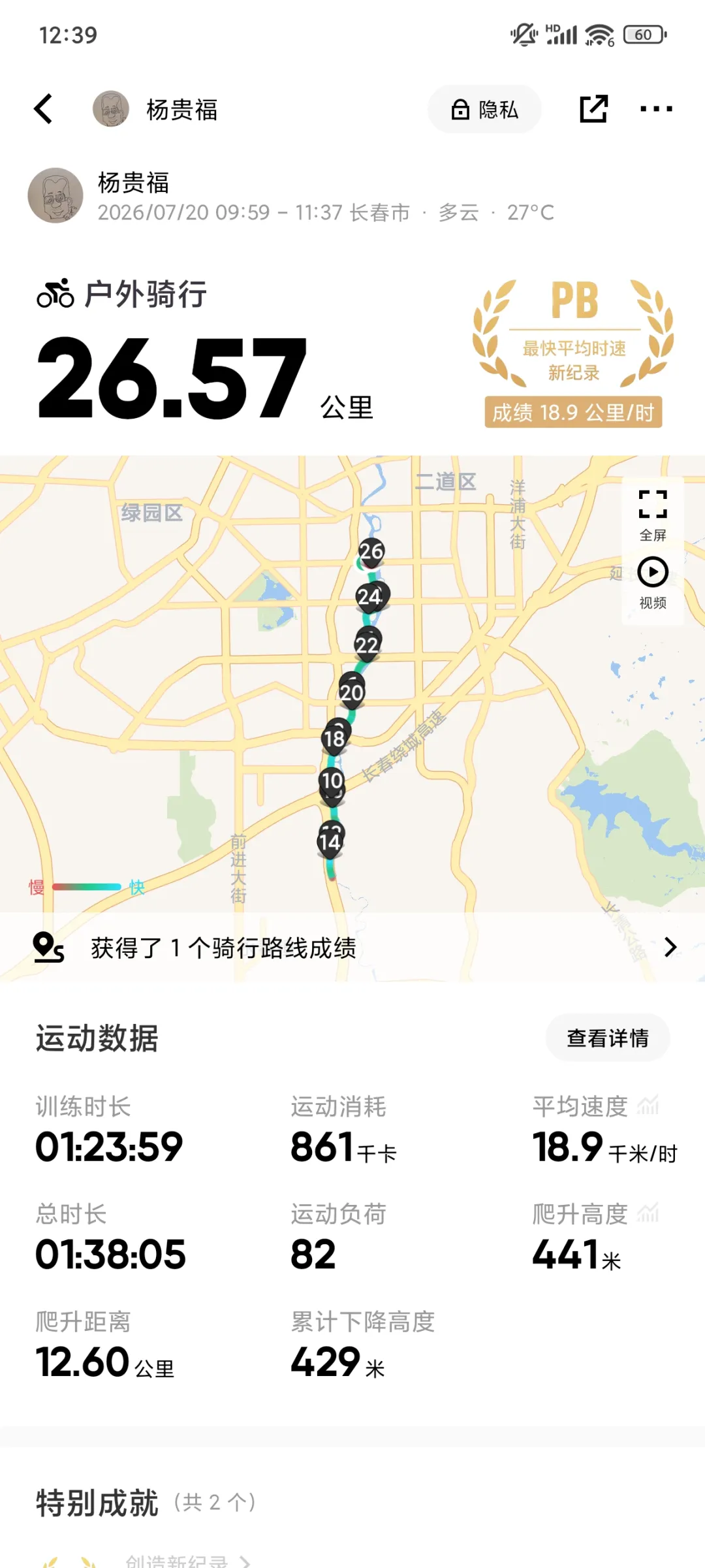
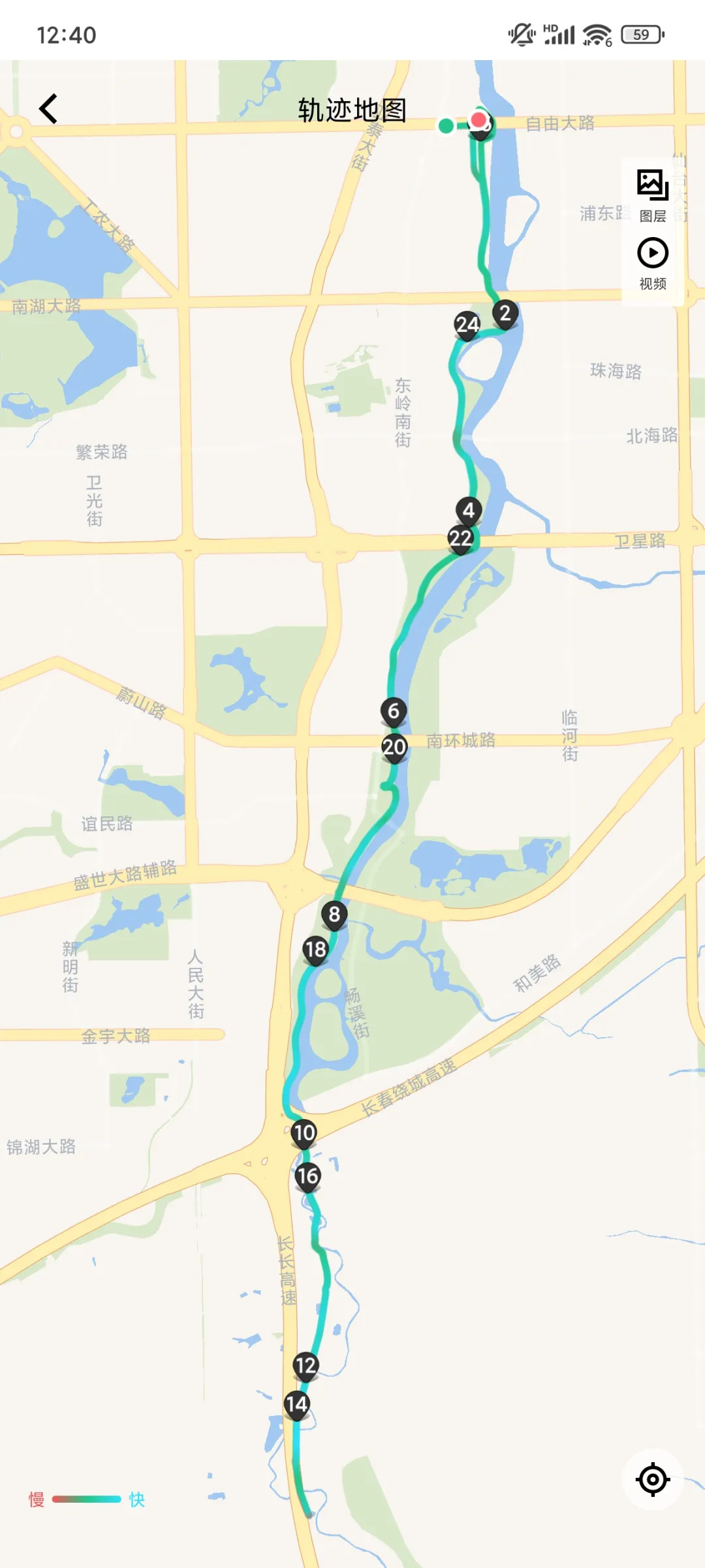
昨天提到,我大约每两座桥休息一次,喝口水。今天听了一下keep报告,发现这么做是有原因的。回家用百度地图量了一下,每两座桥之间大概接近4公里。一共三段,共12公里左右。往返加上曲折,一共26公里。我的时速是16~18公里左右。喂,4公里左右,刚好15分钟左右。
有的桥下有点儿臭,可能因为水流缓慢。或是有点儿发霉的味儿。不过,人们还是喜欢在这里聚集,凉快吧。
今天又看到了打羽毛球的,踩高跷的。踩高跷的放着曲儿,师傅对徒弟说,今天咱们就练踩点儿,别的什么都不练。字正腔圆,说不定还是戏剧出身。


还有钓鱼的,对着坐着,也就是对着河对面的我。看不到吊杆儿和钓线,这些大爷看着就在河边洗衣服,缺个棒槌,就是浣纱女。后面还有个小桌子,几个人围那会着,身体前倾,全情投入,说不定在搓麻将。再仔细一看,三个人。一会儿可能就喊看钓鱼的,嘿,别看了,三缺一等你呐。
他们的后面也是骑行道,一会儿过去一辆自行车,一会儿过去一辆自行车。骑手和渔夫就像生活在两个不同的世界,距离那么近,但是互相简直看不到。


3. 分区
我用大桥和饮水区把行程单程分成了三段。同时,整个行程也有三段不同的风格。都是三段,不过数字相同完全是偶然的,不是特意在风格分界区休息。
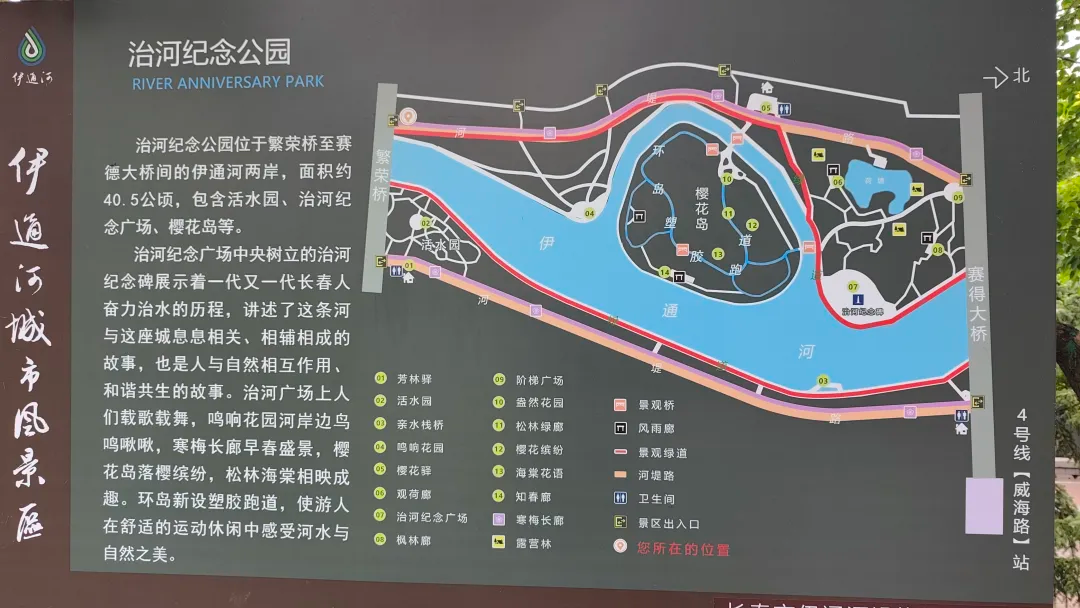
第一段是从自由大路出发,向南到达南溪湿地(高速入口、光影桥、下图中那张左侧有镀铬样的铁塔照片)附近。这一段是市内,危险和麻烦主要来自人群、快递的摩托和电单车。虽然有很多人,但是也有很多野生动物。昨天在经过工业遗迹公园的小路时,一只花鼠从我车轮前通过,我紧急刹车,它也紧急刹车,刚好停在我车门前,差点压到。今天看到了两只花鼠。考虑到我的视力,也许这一路上可能遇到了十只也说不定。花鼠,就是长得有点儿像松鼠,背后三条条纹像仓鼠,尾巴挺长,但是不粗。今天还看到你,一只喜鹊和一只鸽子并地走。如果仔细分析,说不定是鸽子在稳当地走,喜鹊在挑衅,我看到它一跳一跳的。
这一段的路况非常好。有的地方行道树的树冠下遮很深,骑自行车大约齐胸高,不过白天不必担心,很容易看到。
从南溪湿地向南到达肆季南河之前大约一半的行程。这是一段路两侧有很多芦苇,路况尚可。有的芦苇会伸到路面上,白天很容易看到。骑到这里,有些人就累了,在路边休息,会占一排车道。人经常在自行车的后面,所以把一排车道占满。白天容易看到,不必担心。要小心的是,对面来车通常很难考虑到你需要躲避芦苇和树冠,所以可能不会留给你通行的车道。
南溪湿地到肆季南河的后一半行程,路边有很多庄稼。我能看出的就是,黄一条儿是土,白一条儿是作物。至于什么作物我就不知道了,矮株的,要么是茄子,要么是辣椒,看叶子是大的,要不然是灰菜,虽然没人种灰菜。肯定是双子叶,不是单子叶。一大片一大片的,还有农家肥的气味。有新鲜的,还有陈旧的,沤了一段儿时间的。不浓。
这一段路面上有沙子。昨天摔跤,应该就是沙子的原因。昨天回来,跟二猫妈讲摔跤的事儿。二妈妈说,是不是路上有沙子,我是没注意。今天注意了一下,很多隔一段就有一小条儿。应该是施工遗留的,没有人清理,黄沙。看起来干净的地方,傻子只是少,而不是没有。被来往的车带到了这里,这样就更危险。还有的路面有黄土,应该是下雨或者洪水冲的,从农田一直延伸到河滩,沿着路面三五米到十米长。因为黄土被阳光晒硬了,所以骑的时候要握住车把,小心一点儿,沿着车辙,不要拐弯,不然容易倒。
有很多壮丽的高压塔,高速公路架空的桥,大片的农田和野草,白杨林。没修完的桥,只有桥墩立在水中,也可能是某种水利设施。
不打算再去自由大路向北了,特别是晚上。路上全是人,赶集一样,站满了徒步道和自行车道,都并排走。还有和小狗儿并排走的,狗是棕色的脚踝骨那么高,人和狗之间有绳子,占三排道,狗一排,人一排,绳子一排。绳子和狗在光线不好的时候都很难看到,相当危险。树冠非常多向下也齐胸高,同时路比南边窄很多,晚上的时候简直是致命武器。溜小孩儿的有很多,和家长相距10米左右,突然就窜出来了。目标又小,行动又突然,根本反应不过来,太可怕了。




4. 雨量充沛
从四五年前开始,长春的雨量在夏天变得非常充沛。而且是那种突然就下的雨,一下就很大。我小的时候很少有这种,上一次印象里还是初二的时候要分班,那场雨下得很大,打伞都没有用。我们写了小纪念卡,每人一张,上面写着“我们虽然不能生活在一起,我们永遠也不会分离”。那是《侠胆雄狮》中的台词,温森特的独白。我们班后来没分,分的是别的班。
现在经常遇到雨,没有准备就挨浇。我说这是啥天气呀。偶像说,他小的时候,老家的天气就是这样,说下就下。我说,那怎么办呢。他说,就找个地方避雨呗,雨停了再接着走。很有道理。
今年的雨量格外充沛,比前几年还要严重。而且还热,又热又闷,我抱怨自己快要发霉了,朋友圈告诉我,梅雨季节。是挺像地理书中的梅雨季节,然而这是东北的长春啊!
雨热同季,植物格外高大。蒲公英长得比我的手掌还大。鬼针草,还是一年蓬长到齐肩高。向北去那天,路标不清楚,回归主路要穿过一条小径,两边的草已经把小径的上方,骑车齐肩高的地方遮满了。低头看不到路,只能努力向前骑,祈祷前方没有沟。




5. 上游放水了
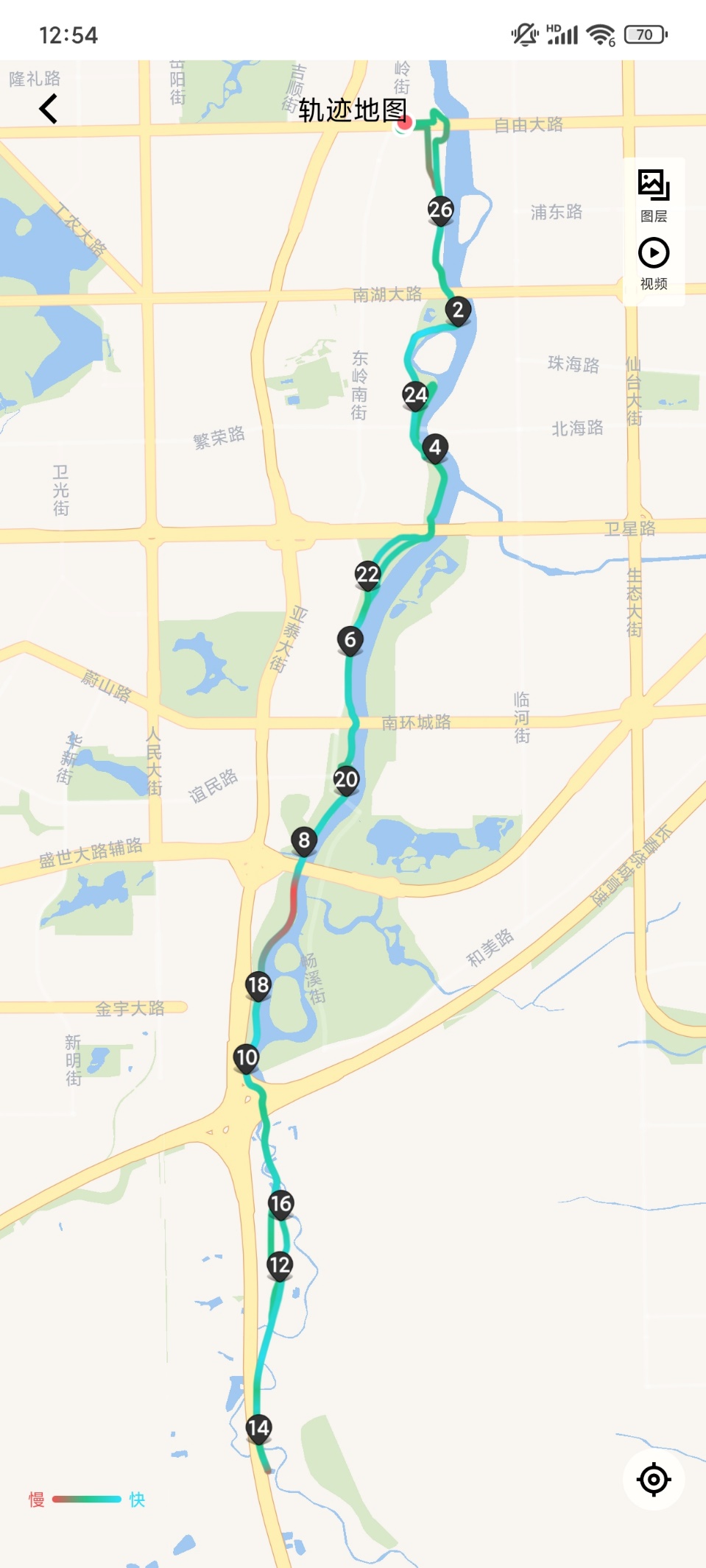
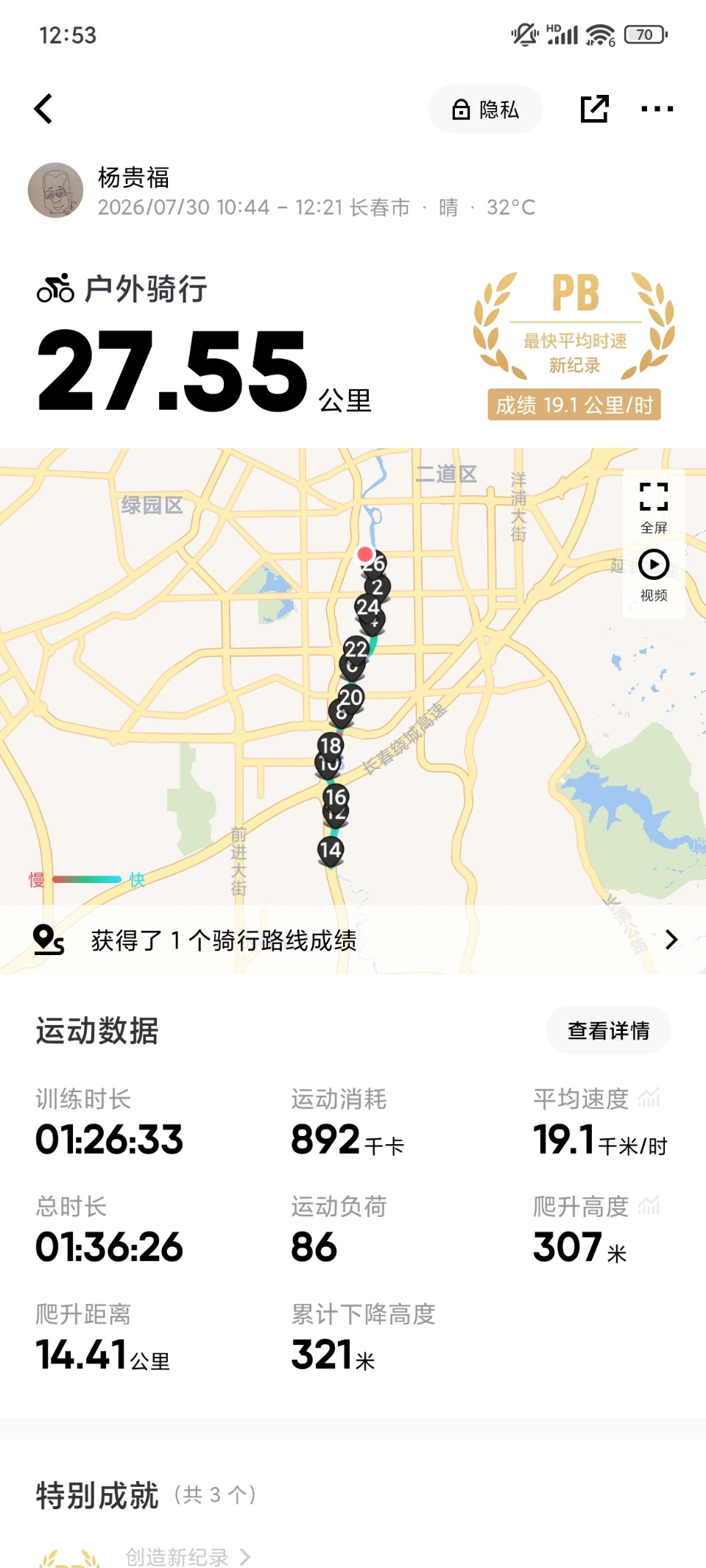
从自由大路向南的时候总是感觉艰难,向北的时候要轻松很多。从时速上也能看得出来,江楠,十三四公里每小时,向北很容易达到20。我原以为是前10分钟达到极限反应之前的体验造成的错觉。今天突然想到,伊通河自南向北穿过长春。我向南的时候是沿伊通河上溯,向北的时候是沿伊通河下行。虽然河流缓慢,路面较平,但是仍然应该是有落差的,身体感受到了。
今天快要到达四季南河的时候,听到瀑布的声音。我想到应该是上游水库,也就是新立城放水了,以应对接下来几天可能到达吉林省的暴雨。
绕过水闸,瞬间瀑布的声音就消失了。看来虽然听起来宏大,但是主要的成分应该是较高的频率,绕射能力差。2000Hz以上?
对比今天和昨天的照片,能够看到,根据那几根水泥管看确实放水了,水面有所提升。

回到瀑布的下面,拍了几张照片。注意到有撒网捞鱼的,有下笼子的。还有钓鱼的,旁边就是禁止钓鱼的大牌子。还有3个小伙儿正从河底下走上来,边走边说,哎,那面儿也有水。他们指的是京哈高速架空桥的下面,原本是平地,现在已经变成了很大一片水塘。听说伊通河有三四十斤的鱼,不知道会不会顺着水库放水出来更大的大鱼。
再向下游就能看到,还没有到市区,水面就跟平时没有什么区别了。




此文也发布在以下站点。
----
独立博客 https://younggift.net/
微信公众号 杨贵福
----
以下是我曾经发布博客的站点,有些旧文。
----
知乎两次误判我发的视频为“垃圾、营销”,禁言我的账号。不接受审核,不再更新。
知乎 https://www.zhihu.com/people/yang-gui-fu-52
豆瓣 - 因为审核"我的日记",不再更新。
https://www.douban.com/people/younggift/?_i=0098558fqLUL9h
CSDN – 因为要求我登记手机号码的原因是“为了您的安全”,不再更新。
https://blog.csdn.net/younggift?type=blog
blogsopt – 因为从我的机器不可达,无法更新